
Yesterday I was asked “What makes a great Data Scientist?” so I gave a few short quick-fire answers trying to replace “great” with “good” in the question:
“Knowing when it is ok to apply a tree-based boosting machine to a regression problem and why you might need non-deterministic tree training.”
“Knowing how to merge a deep vision technique and a neural NLP one in order to obtain a powerful business predictive analytics model.”
“Understanding how a business process generates data,
how that data can be extracted, how the extracted data can be remodeled
in order for it to be fed to state-of-the-art models, and finally, how that trained model
will come back to the business process with real improvements.”
“Finding the best pre-trained classification model for the task of preparing and clustering unlabeled cross-domain data.”
“Not getting attached to your beloved framework and being flexible enough to understand that you might need to do your initial research in Keras, train the model with an exotic constrained loss in TensorFlow in a carefully babysitting manner and then deploy the model in production on your TX2 using TensorRT.”
Then, after thinking more thoroughly, I gave a more extensive and broader answer and it actually become increasingly apparent that the definition of the “Data Scientist” concept evolves day-after-day, together with the slow adoption of big-data machine learning in our lives – at work and at home. What I think is really important, probably the most vital consideration, is the combination between multi-domain experience and a firm resolve to continuously explore, understand and evolve.
Multi-domain (or cross-domain if you want) experience allows the Data Scientist to truly understand the natural processes that are being observed. Obviously enough, following the ‘understanding’ comes the actual hypothesis formulation and testing stage and then the rest of the usual steps.
I have seen a myriad of data science experts and machine learning practitioners with a wealth of experience making statements such as: “the best model can be a simple logistic regression with well-chosen features” or “using a deep neural model only increases by a few percent the model accuracy versus the shallow model based on well-chosen-features” or “the self-explain ability of the linear model cannot be traded for the black-box-style of a neural model”. While there is a high probability that most of the time this is true, over the past 5 years it has been repeatedly demonstrated that new deep-learning research from various domains can be successfully applied to another domain. Take for example deep neural models from NLP research such as word2vec (https://arxiv.org/pdf/1301.3781.pdf) or GloVe (https://nlp.stanford.edu/pubs/glove.pdf) applied with great proven success in recommender-system by various research groups; the list could continue, but that is beyond the point of this post.
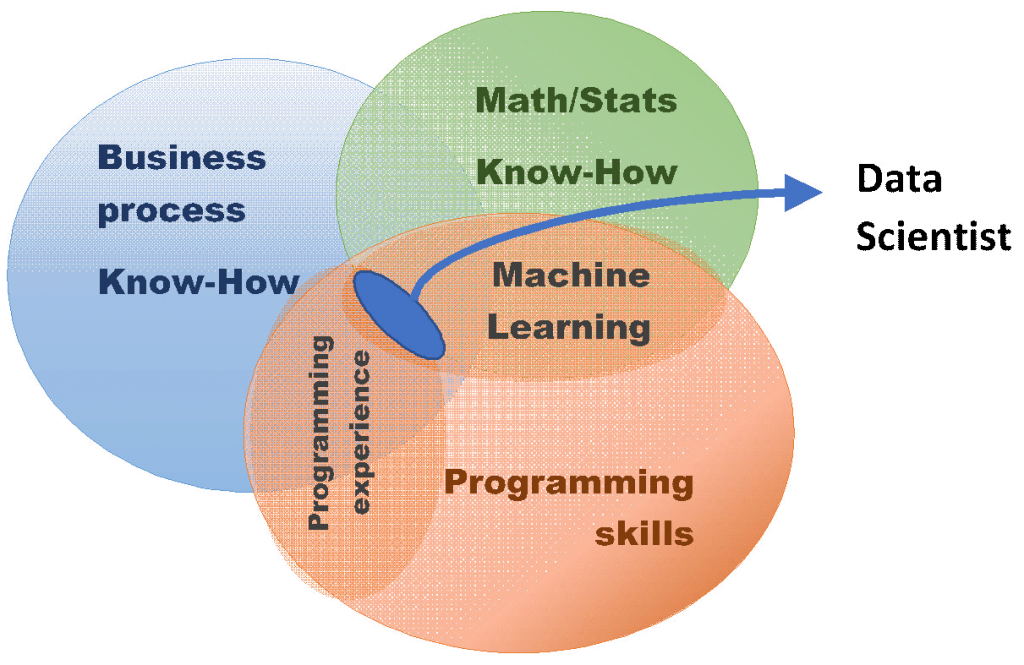
To conclude, I think the Data Scientist profile must have the optimal combination between several intersecting domains (perhaps the diagram above is a clearer representation of these concepts) and should not exclude – under any circumstances – the active research and continuous analysis of the current state-of-the-art in Deep Learning and adjacent areas. I really don’t think there are any short-cuts nor acceptable uncovered knowledge zones.


